Quoi de neuf dans le serverless
La distribution automatique de la logique et des données à la périphérie réduira la latence au minimum pour les utilisateurs finaux, sans que les développeurs aient à se préoccuper du provisionnement, de la mise à l'échelle ou de la configuration.
Les services serverless ont envahi le paysage IT. Fer de lance d'une nouvelle approche de la programmation, les offres serverless ont adopté toutes les formes : plates-formes d'hébergement applicatives, bases de données, réseaux CDN de diffusion de contenu, offres de sécurité, etc. Surtout, elles permettent d'éviter les problèmes de configuration, de mise à l'échelle et de provisionnement de bas niveau pour se concentrer uniquement sur la distribution. Quant à l'edge serverless, il apporte une solution en redistribuant les données et le traitement entre plusieurs datacenters. Il réduit la latence en rapprochant le processus de traitement de l'utilisateur. L'edge serverless achève une évolution des architectures cloud entamée il y a près de 15 ans avec l'Infrastructure-as-a-Service (IaaS) dont la prochaine étape consistera à pousser plus loin la distribution de « blocs de construction » serverless et de faciliter leur consommation par les développeurs.
Fonction en tant que service (FaaS)
Le FaaS permet de télécharger et d'exécuter du code sans avoir à penser à la mise à l'échelle, aux serveurs ou aux conteneurs. En ce sens, sa facilité d'emploi surpasse celle des offres précédentes. Mais, par rapport aux plateformes en tant que service (PaaS), il a ses limites. Le plus gros avantage du FaaS réside dans la mise à l'échelle : il permet une granularité plus fine que le PaaS, et même le CaaS (Contenu en tant que service), et il n'a pas besoin d'être configuré. De plus, avec le FaaS, on ne paye que pour ce qu'on utilise.
- Granularité : les applications PaaS ne mettent généralement à l'échelle que par application, tandis que les applications construites sur CaaS ne mettent à l'échelle que par conteneur. Les applications FaaS sont décomposées en fonctions distinctes et donc mises à l'échelle par fonction. L'inconvénient, c'est que cela oblige souvent à repenser l'architecture de l'application. Au lieu de gérer une seule application ou quelques conteneurs, il faut gérer de nombreuses fonctions qui exécutent des tâches plus petites, ce qui peut nécessiter beaucoup de travail d'orchestration.
- Configuration : normalement, la configuration se fait au moment de la mise à l'échelle (avec des déclencheurs pour augmenter et réduire l'échelle) ou bien l'on doit définir manuellement combien d'instances d'une application ou d'un conteneur il faut exécuter. Dans une architecture FaaS, il n'est pas nécessaire de configurer la mise à l'échelle, ni de provisionner des ressources spécifiques.
- Pay-as-you-go : au lieu de déployer des conteneurs (CaaS), pour lesquels il faut payer, que le code soit activement exécuté ou pas, le FaaS ne suscite des frais que lorsque les fonctions sont appelées. Ce modèle de tarification pay-as-you-go devient peu à peu l'élément le plus important pour définir le « serverless ».
- Limites : Pour une application courante, on peut définir des limites de mémoire ou des limites de temps d'exécution pour le code. Même si les fournisseurs de FaaS permettent de les configurer, il peut y avoir des limites supérieures qui permettent au fournisseur d'optimiser efficacement ces ressources. On peut imaginer qu'un fournisseur aurait beaucoup plus de mal à estimer le nombre de serveurs qu'il doit exécuter pour utiliser ses ressources de manière optimale si les fonctions peuvent être créées avec 10 Go de mémoire vive ou peuvent fonctionner pendant quelques heures.
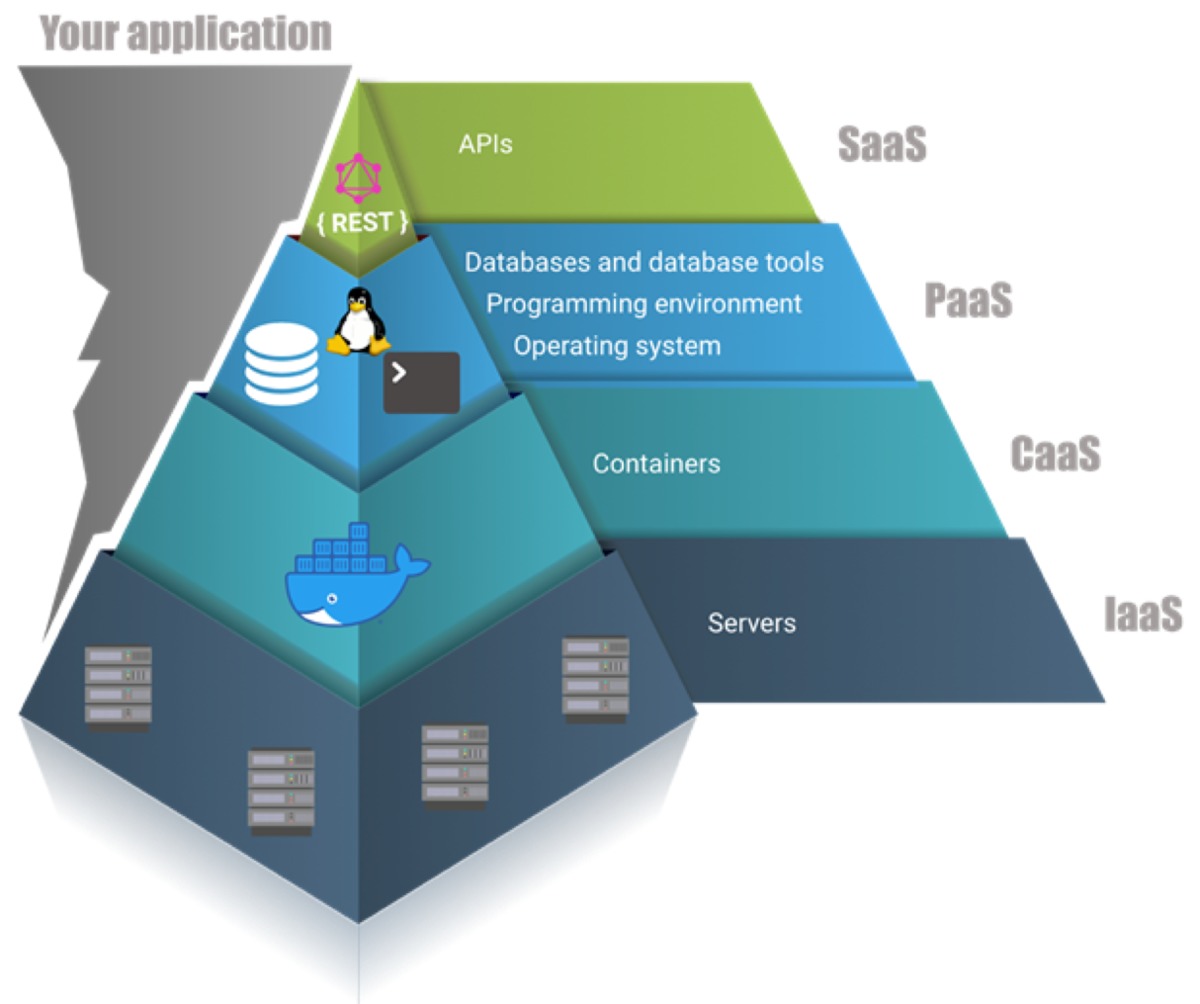
De nombreuses applications complexes sont une combinaison de SaaS, PaaS et CaaS.
Une nouvelle architecture edge
L'architecture serverless a permis d'éliminer les problèmes de provisionnement et de mise à l'échelle, mais la distribution reste un problème compliqué. Dans l'idéal, chacun veut que le code soit exécuté au plus près de l'utilisateur final pour réduire la latence. Mais, la manière dont ont été développées les applications, jusqu'à récemment, pose de multiples problèmes :
- Distribution logique : à moins de déployer les fonctions ou les conteneurs dans différentes régions, et d'acheminer soi-même le client vers la fonction la plus proche, toute fonction était généralement exécutée dans un seul datacenter.
- Distribution de données dynamiques : distribuer la logique sans distribuer les données n'est pas très rentable, car la latence se déplace ailleurs. L'utilisateur peut éventuellement se trouver plus près du back-end, mais le back-end reste toujours éloigné de la couche de données.
- Coût, configuration, surveillance : Il est rare qu'une application soit distribuée dans plus de deux ou trois régions, car cela implique généralement un coût ou une configuration supplémentaire et impose de surveiller les fonctions ou les conteneurs dans plusieurs régions.
Une prochaine évolution du « serverless » consistera à pousser la distribution plus loin et à effectuer la livraison sans avoir besoin de la configurer. Cela signifie que la logique et les données seront distribuées dans de nombreuses régions du monde, ce qui réduira efficacement la latence pour les utilisateurs finaux.
CDN et Jamstack
Un réseau de distribution de contenu, ou Content Delivery Network (CDN), est une forme élémentaire et courante de service de distribution automatique. Quelques esprits brillants, dans des entreprises comme Netlify et Zeit, ont compris que la distribution automatique pouvait déjà être réalisée en pré-générant l'application autant que possible, et en traitant les parties dynamiques avec des fonctions serverless et des API SaaS. Cette approche, baptisée « Jamstack » par Netlify, a rapidement gagné en popularité, car les réseaux de diffusion de contenu préfigurent de ce que pourrait offrir une architecture edge. Bien sûr, parce que l'approche Jamstack est basée uniquement sur un rendu côté serveur, elle a ses limites. Par exemple, il faut déclencher des builds pour tout nouveau contenu entrant. Il est donc très difficile d'appliquer cette approche à des sites web hautement dynamiques qui ont des temps de construction importants.

Les Jamstacks basées sur le rendu côté serveur ne conviennent pas aux sites web hautement dynamiques, car les builds doivent être déclenchées pour les nouveaux contenus. (Crédit : Fauna)
Les builds incrémentielles et des concepts comme « l'hydratation côté client » offrent des solutions partielles à ce problème. Mais au final, chacun veut que ses sites web complexes offrent les avantages des deux mondes : des latences (très) faibles pour les utilisateurs finaux et un nouveau contenu accessible immédiatement.
L'essor des services distribués
Classiquement, une architecture front-end communique avec une architecture back-end, et le back-end communique à son tour avec la base de données et d'autres services. Le back-end et la base de données sont souvent mis à l'échelle ensemble pour maintenir une faible latence entre le back-end et la base de données. La distribution est possible, mais souvent lourde et donc limitée.
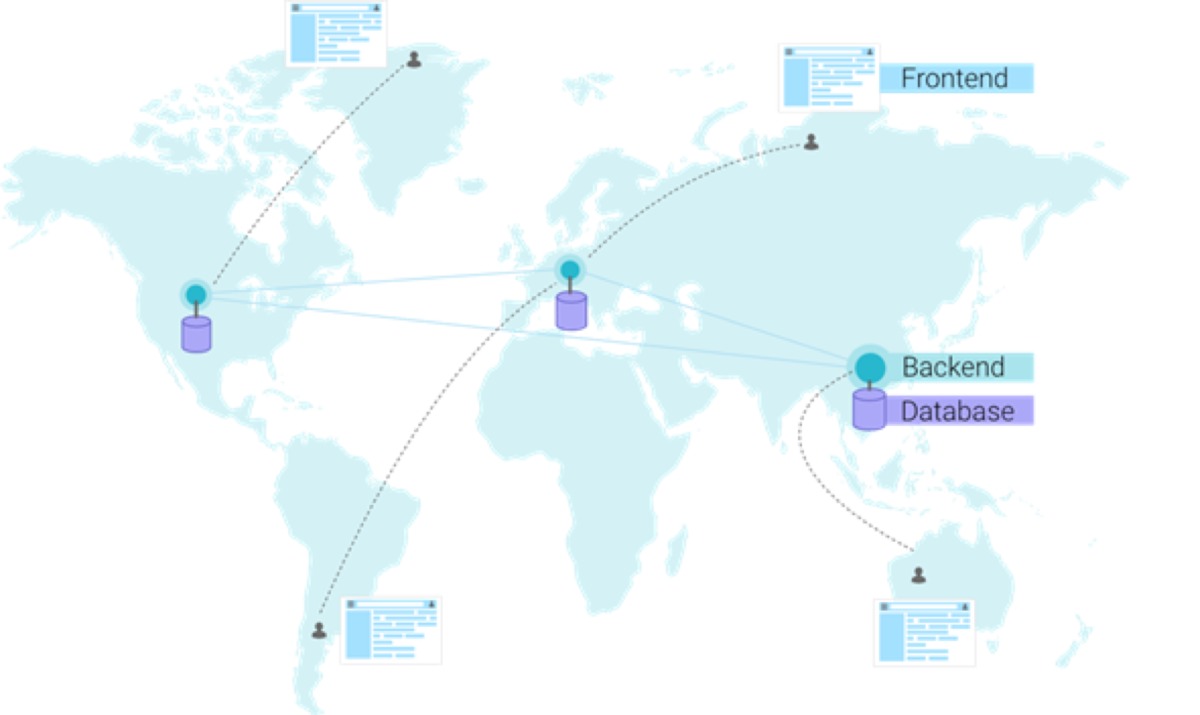
La distribution du back-end et de la base de données est possible, mais souvent lourde et donc limitée. (Crédit : Fauna)
Dans les futures architectures, le concept de Jamstack sera porté plus loin en utilisant d'autres services distribués. Chacun de ces services aura la forme d'un réseau distribué dont les noeuds ne seront pas nécessairement exécutés dans le même datacenter que les autres services. Pour réduire la latence à un minimum absolu, le modèle de sécurité doit être repensé afin de laisser le frontal communiquer avec la base de données et les autres réseaux de services.
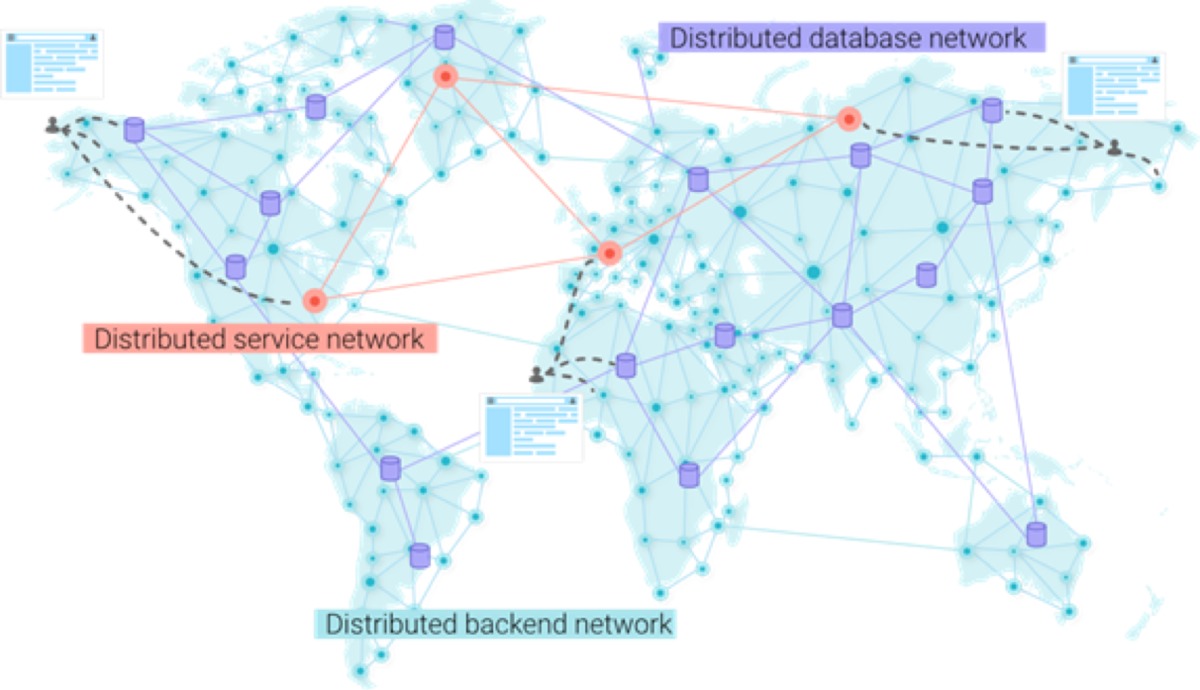
Les futures architectures d'application tireront parti des réseaux de services distribués, des réseaux de bases de données distribués et des back-ends serverless distribuées. (Crédit : Fauna)
Voici les services qui permettront de pousser ce concept :
Réseaux de services distribués
De nombreuses plateformes SaaS, comme Algolia et SendGrid, envisagent de servir de blocs de construction à d'autres applications. Elles développent pour cela des services spécifiques qui éliminent les problèmes posés par les applications back-end typiques. Certaines plateformes évoluent en services distribués. C'est le cas d'Algolia par exemple qui se définit elle-même comme un réseau de recherche distribué ou Distributed Search Network (DSN). Plusieurs autres plateformes SaaS devraient suivre l'exemple et les réseaux de services distribués seront bientôt considérés comme la prochaine évolution des applications SaaS.
Bases de données serverless distribuées
Des bases de données comme Azure Cosmos DB, Google Cloud Spanner et FaunaDB adoptent le modèle serverless pay-as-you-go et fournissent une distribution prête à l'emploi avec une certaine forme de garantie ACID (atomicité, cohérence, isolation et durabilité). Certaines bases de données offrent des couches de sécurité et des API GraphQL natives qui peuvent être consommées en toute sécurité par les applications clientes et qui fonctionnent bien avec un back end serverless. Les couches de sécurité permettent aux interfaces utilisateur d'interagir directement avec la base de données au lieu de se contenter d'un back-end. Idéalement, une application front-end peut communiquer avec une base de données distribuée globale avec de faibles latences et des garanties ACID, presque comme si la base de données fonctionnait localement.
Informatique edge serverless distribuée
De nouvelles fonctions serverless, comme Cloudflare Workers et StackPath Serverless Scripting, orientent les fonctions serverless vers l'informatique edge. Elles visent à rapprocher le plus possible les fonctions de l'utilisateur final afin de réduire la latence au minimum absolu. Cloudflare Workers offre 194 points de présence et StackPath offre plus de 45 emplacements.
Pour quelle raison cette nouvelle architecture edge gagne-t-elle en popularité aujourd'hui ? Quand on regarde l'évolution de l'IaaS jusqu'à l'edge serverless, on constate que cette transformation a toujours été entravée par un obstacle majeur : celui de la gestion des données dynamiques. Même si des services comme Amazon S3 permettent d'héberger des données relativement statiques, les vraies bases de données ont eu du mal à offrir une expérience serverless. Et pour une bonne raison : il est extrêmement difficile de construire un système distribué fortement cohérent.
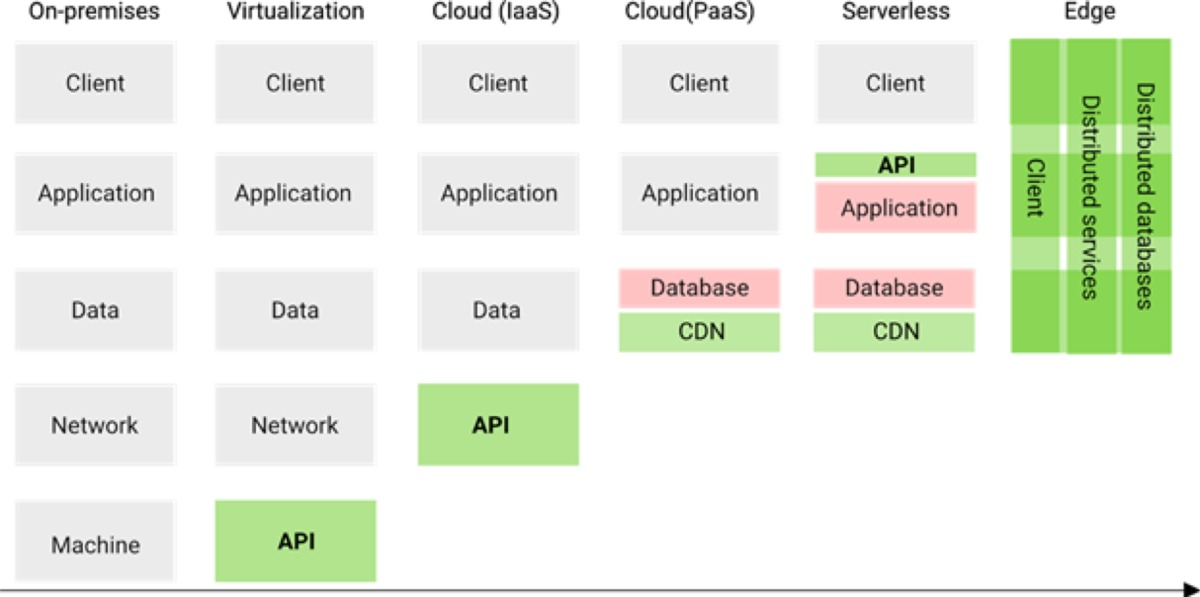
Les blocs de construction serverless dans le cloud fonctionnent comme des Legos. Les développeurs peuvent combiner les blocs de construction dont ils ont besoin sans se préoccuper de la mise à l'échelle ou de la distribution. (Crédit : Fauna)
Aujourd'hui, des bases de données serverless avec sécurité intégrée ouvrent la voie à un nouveau type d'applications - des applications qui, par défaut, se mettent à l'échelle de manière globale. Depuis que cette voie est ouverte, de nombreux développeurs cherchent des solutions pour remplacer certaines parties de leur système back-end par des micro-services et des API, ouvrant ainsi un nouveau marché pour de nombreux fournisseurs SaaS. Au final, tout cela débouchera sur un écosystème de blocs de construction qui fonctionnent comme des Legos. Bientôt, les développeurs pourront combiner les blocs de construction dont ils ont besoin et ne se préoccuperont plus, ni de la mise à l'échelle ni de la distribution.