Cisco muscle sa famille Silicon One
Les deux puces Silicon One programmables haut de gamme ajoutés par Cisco peuvent prendre en charge des clusters GPU massifs pour les charges de travail d'IA/ML.

Les puces Silicon One programmables (5 nm) dévoilées par Cisco sont destinées à soutenir les infrastructures dédiés à l'intelligence artificielle (IA) et d'apprentissage machine (ML) à grande échelle des entreprises et des hyperscalers. Les circuits Silicon One G200 (51,2 Tbps) et G202 (25,6 Tbps) font passer la famille Silicon One à 13 unités. Chaque chipset est personnalisable pour le routage ou la commutation, si bien qu'il n'est plus nécessaire de disposer d'architectures de silicium différentes pour chaque fonction réseau, et ce grâce à un système d'exploitation commun, un code de transfert programmable P4 et un kit de développement logiciel (SDK).
Selon Rakesh Chopra, Cisco Fellow au sein du Common Hardware Group du fournisseur, les équipements positionnés au sommet de la famille Silicon One apportent des améliorations idéales pour les déploiements AI/ML exigeants ou d'autres applications hautement distribuées. « L'industrie est en train de vivre un énorme changement. Jusque-là, nous avions l'habitude de construire des sortes de clusters de calcul haute performance raisonnablement petits qui semblaient grands à l'époque, mais ce n'était rien comparé aux déploiements absolument gigantesques requis pour l'IA/ML », a déclaré M. Chopra. Les modèles d'IA/ML sont passés de quelques GPU à des dizaines de milliers reliés en parallèle et en série. « Le nombre de GPU et l'échelle du réseau sont sans précédent », a-t-il ajouté.

La famille Silicon One comprend désormais 13 puces programmables dédiées au routage ou à la commutation. (Crédit Cisco)
Support des fonctions Ethernet améliorées
Parmi les améliorations apportées par Silcon One, le dirigeant pointe le processeur de paquets parallèles programmable P4 capable de lancer plus de 435 milliards de recherches par seconde. « Le tampon de paquets est entièrement partagé, et chaque port a un accès complet au tampon de paquets, indépendamment de ce qui se passe », a expliqué M. Chopra. C'est très différent de l'attribution de tampons à des ports d'entrée et de sortie individuels, laquelle fait dépendre le tampon du port auquel sont destinés les paquets. « Cette attribution limite la capacité à écrire à travers les rafales de trafic et expose davantage au risque de laisser tomber un paquet, ce qui diminue vraiment les performances de l'IA/ML », a-t-il encore expliqué. « Par ailleurs, chaque dispositif Silicon One peut prendre en charge 512 ports Ethernet, ce qui permet aux clients de construire un cluster AI/ML 32K 400G GPU avec 40 % de commutateurs en moins que les autres dispositifs silicium nécessaires pour prendre en charge ce cluster », a ajouté M. Chopra.
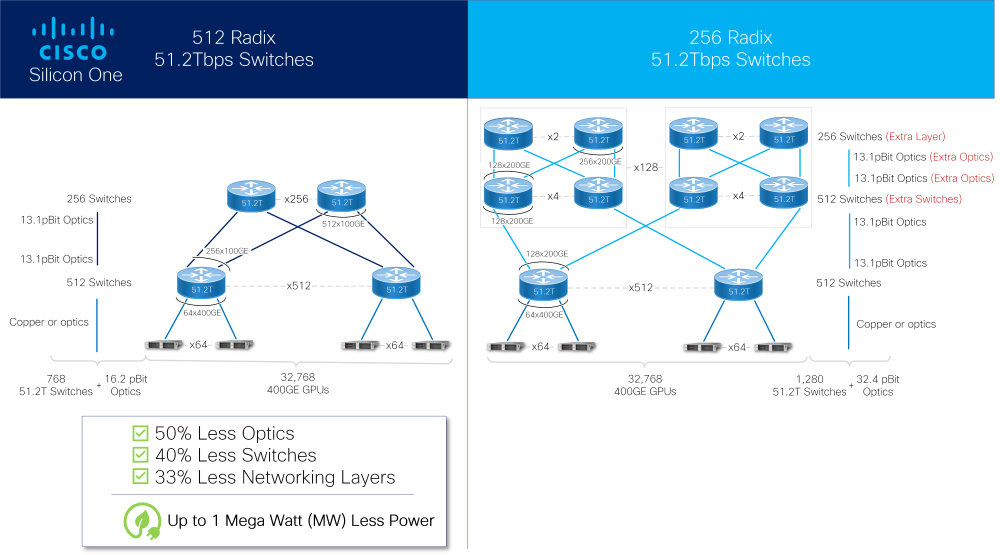
Les performances du circuit G200 de quatrième génération décuplent le débit théoriques de la famille Silicon One. (Crédit Cisco)
La fonction essentielle du circuit Silicon One consiste dans la prise en charge des fonctions Ethernet améliorées, comme le contrôle de flux, la détection et l'évitement des congestions. Le composant intégre également des capacités avancées d'équilibrage de charge et de « pulvérisation de paquets » - ou « packet-spraying » - qui répartissent le trafic sur plusieurs GPU ou commutateurs afin d'éviter les encombrements et améliorer la latence. « La récupération des défaillances de liaison basée sur le matériel permet aussi de garantir que le réseau fonctionne avec une efficacité maximale », a déclaré le fournisseur.
En route vers la Scheduled Fabric
En combinant ces technologies Ethernet améliorées et en les poussant plus loin, les clients peuvent finalement mettre en place ce que Cisco appelle un fabric programmé ou Scheduled Fabric. « Dans un Scheduled Fabric, les composants physiques - puces, optiques, commutateurs - sont reliés entre eux comme dans un grand châssis modulaire et communiquent les uns avec les autres pour fournir un comportement de planification optimal », a déclaré M. Chopra. « Au final, le débit de bande passante est beaucoup plus élevé, en particulier pour les flux d'IA/ML, ce qui permet d'obtenir un temps d'exécution des tâches beaucoup plus court du fait que les GPU fonctionnent beaucoup plus efficacement », a-t-il ajouté. « Avec les appareils et les logiciels Silicon One, les clients peuvent déployer autant de fonctionnalités, en plus ou en moins, qu'ils le souhaitent », a encore déclaré M. Chopra.
Cisco n'est que l'un des acteurs de ce marché des réseaux pour l'IA en pleine croissance à côté de Broadcom, Marvell, Arista et d'autres. Selon un blog récent du 650 Group, ce marché devrait atteindre 10 milliards de dollars d'ici à 2027, contre 2 milliards de dollars aujourd'hui. « Les réseaux pour l'IA prospèrent depuis deux ans déjà, date à partir de laquelle nous avons commencé à suivre la mise en réseau de l'IA/ML. Dans nos prévisions, l'IA/ML est considérée comme une opportunité massive pour la mise en réseau et comme l'un des principaux moteurs de la croissance de la mise en réseau des datacenters», indique le blog du 650 Group. « L'impact de l'IA/ML sur la mise en réseau repose sur l'énorme quantité de bande passante dont les modèles d'IA ont besoin pour s'entraîner, les nouvelles charges de travail et les puissantes solutions d'inférence qui apparaissent sur le marché. En outre, de nombreux secteurs verticaux feront l'objet de multiples efforts de numérisation en raison de l'IA au cours des dix prochaines années », a ajouté le groupe. « Les appareils Cisco Silicon One G200 et G202 sont actuellement testés par des clients non identifiés et sont disponibles sous forme d'échantillons », a précisé M. Chopra.